Explore articles
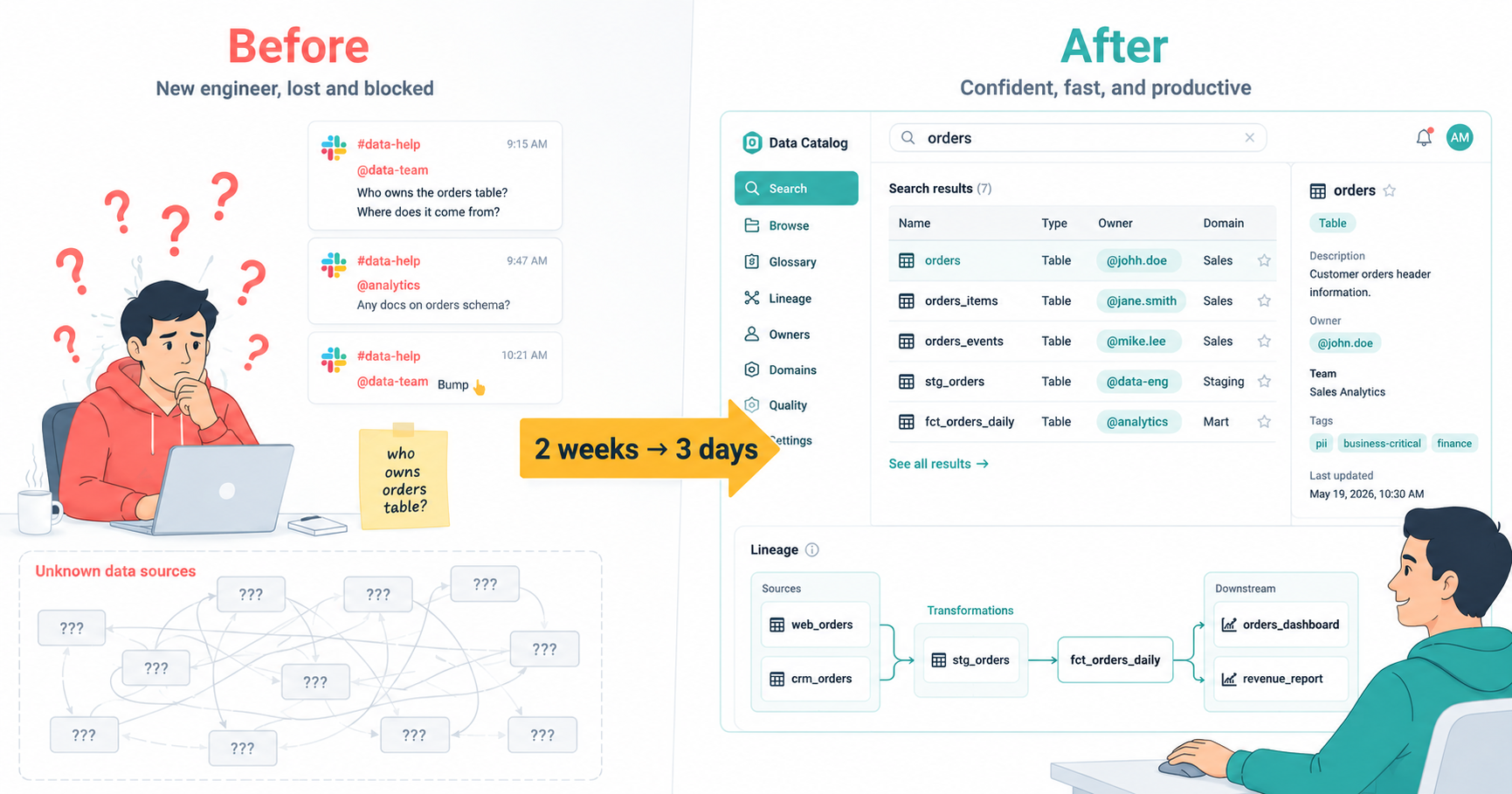
How We Used Purview Data Catalog to Reduce Onboarding Time for New Data Engineers from 2 Weeks to 3 Days
Microsoft Purview Data Catalog is a powerful tool for managing and organizing data assets within an organization. In this article, we share our experience of using Purview Data Catalog to streamline the onboarding process for new data engineers, reducing the time it takes from 2 weeks to just 3 days. We discuss the features of Purview that enabled us to achieve this improvement and provide insights on how other organizations can leverage this tool to enhance their data management practices.
Google Changed Workspace Icon after 6 years
Google has unveiled a new icon design that reflects its commitment to simplicity and accessibility. The updated icon features a more modern

Why Data Engineers Make Better Business Analysts Than MBAs Do
Data engineers often have a deeper understanding of data and its implications for business decisions than MBAs, who may focus more on theory and strategy. This article explores why data engineers can make better business analysts than MBAs, highlighting their technical expertise, problem-solving skills, and ability to derive insights from data to drive informed business decisions.

PySpark Optimization Techniques: 6 Mistakes That Slow Down Every Beginner's Pipeline
PySpark is a powerful tool for big data processing, but it can be challenging to optimize for performance. In this article, we discuss six common mistakes that beginners make when optimizing their PySpark pipelines, which can lead to slow performance and increased costs. We provide practical tips and techniques to help you avoid these pitfalls and improve the efficiency of your PySpark applications.

Azure Data Pipeline Cost Optimization: How We Cut a $4,200 Bill by 73%
Azure Data Pipeline can be a powerful tool for data processing and analytics, but it can also lead to unexpectedly high costs if not managed properly. In this article, we share our experience of optimizing our Azure Data Pipeline costs, which resulted in a 73% reduction in our monthly bill, saving us $3,066. We discuss the strategies we implemented to achieve this significant cost reduction while maintaining the performance and reliability of our data pipeline.
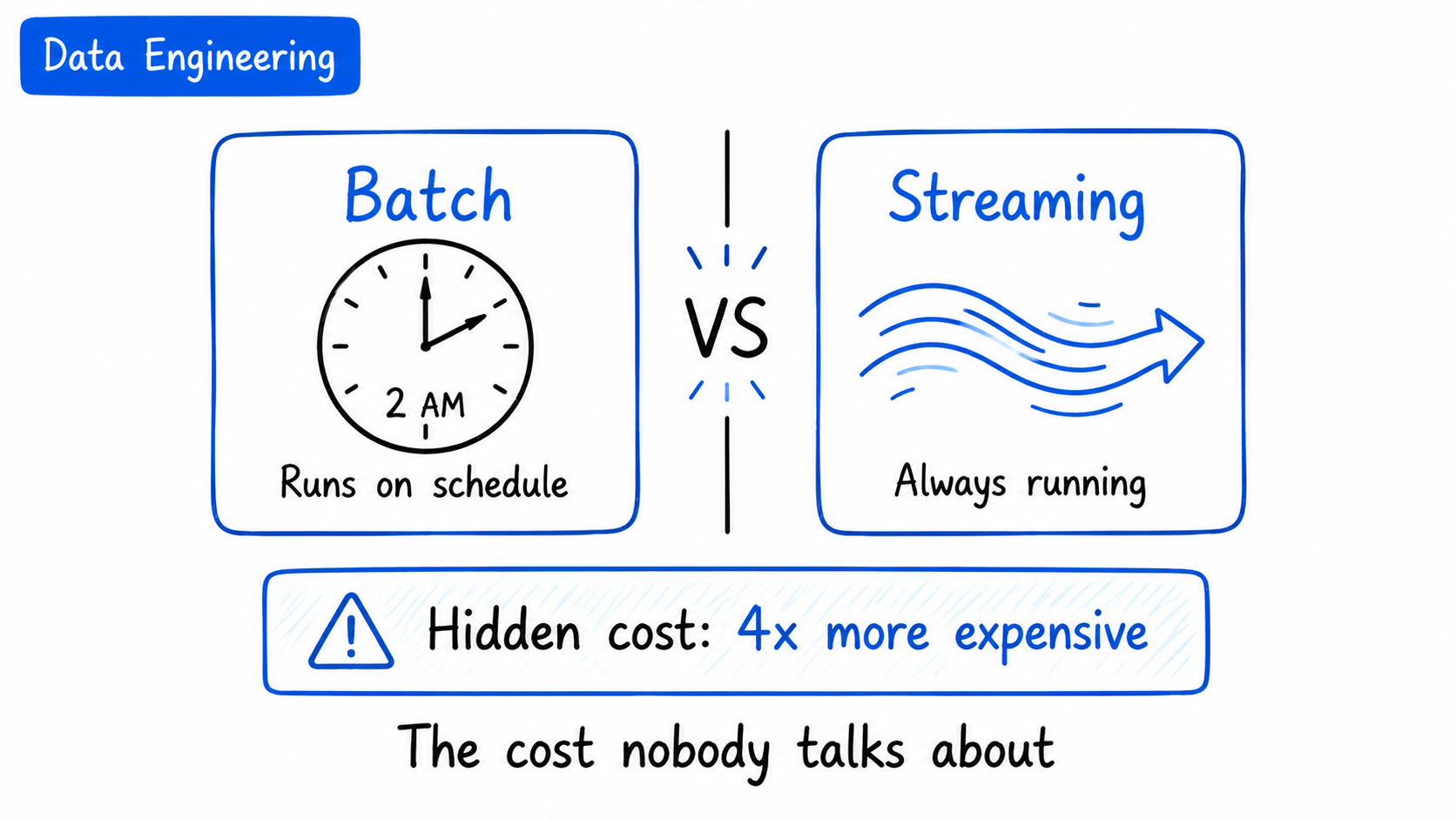
Why We Rolled Back Our Kafka Pipeline to Batch After 6 Months
Streaming pipelines are powerful for real-time data processing, but they come with hidden costs that are often overlooked. These costs include increased complexity, higher resource consumption, and potential challenges in maintaining data consistency and reliability. This article explores these hidden costs and provides insights on how to mitigate them.

Azure Synapse Analytics: When to Use It (And When to Choose Fabric Instead)
Azure Synapse Analytics is a unified analytics service that combines big data and data warehousing capabilities. This article explores when to use Azure Synapse Analytics and when to choose Fabric instead.
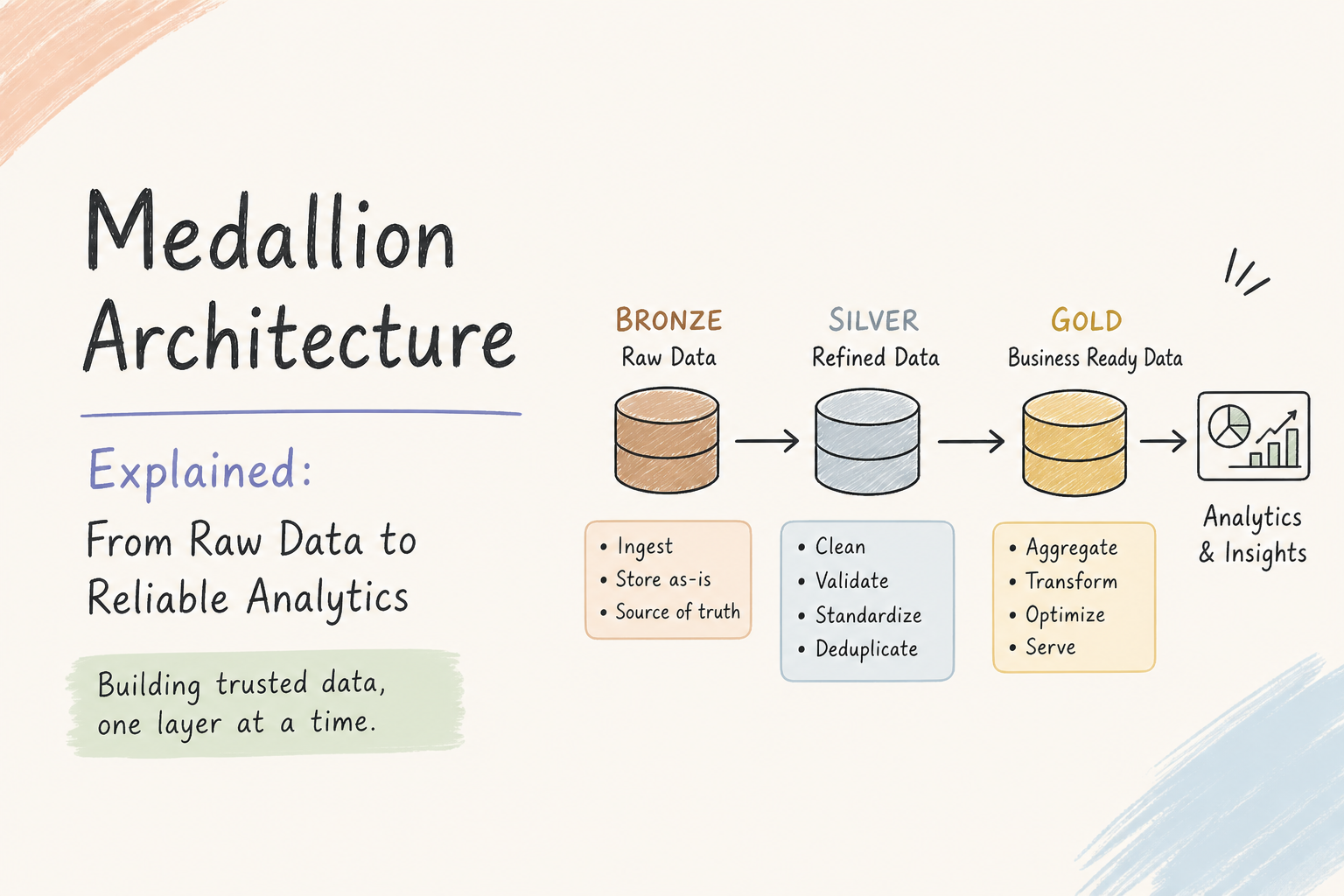
Medallion Architecture: How to Stop Your Data Pipeline from Becoming a Nightmare
The Medallion Architecture is a data management approach that organizes data into different layers (Bronze, Silver, Gold) to improve data quality, governance, and scalability in data pipelines. It helps prevent data pipelines from becoming unmanageable by providing a structured framework for data processing and storage.
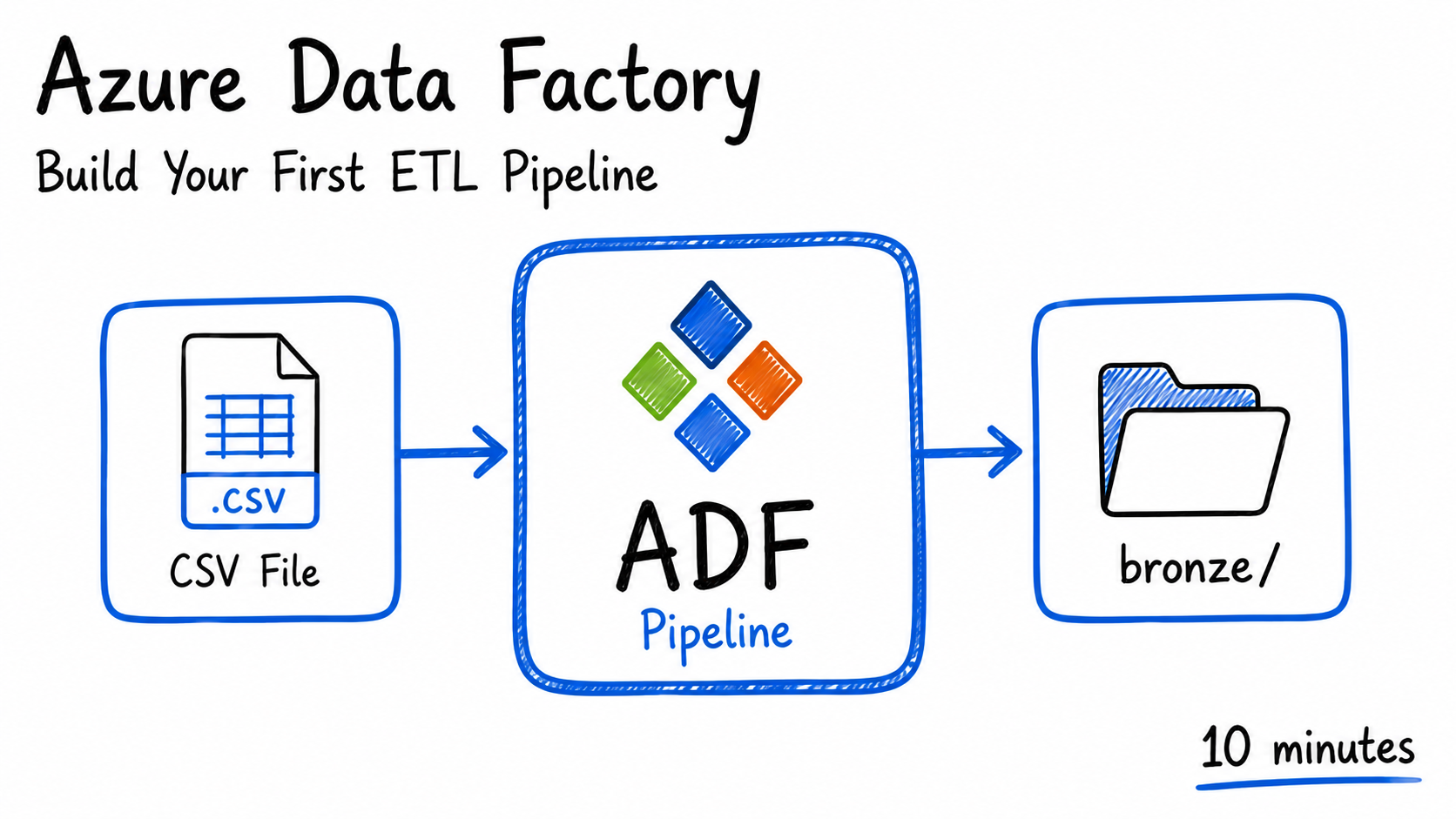
Azure Data Factory Pipeline: Build Your First ETL in 10 Minutes
Azure Data Factory Pipeline is a cloud-based data integration service that allows you to create data-driven workflows for orchestrating and automating data movement and transformation tasks. This article will guide you through the process of building your first ETL pipeline in Azure Data Factory.
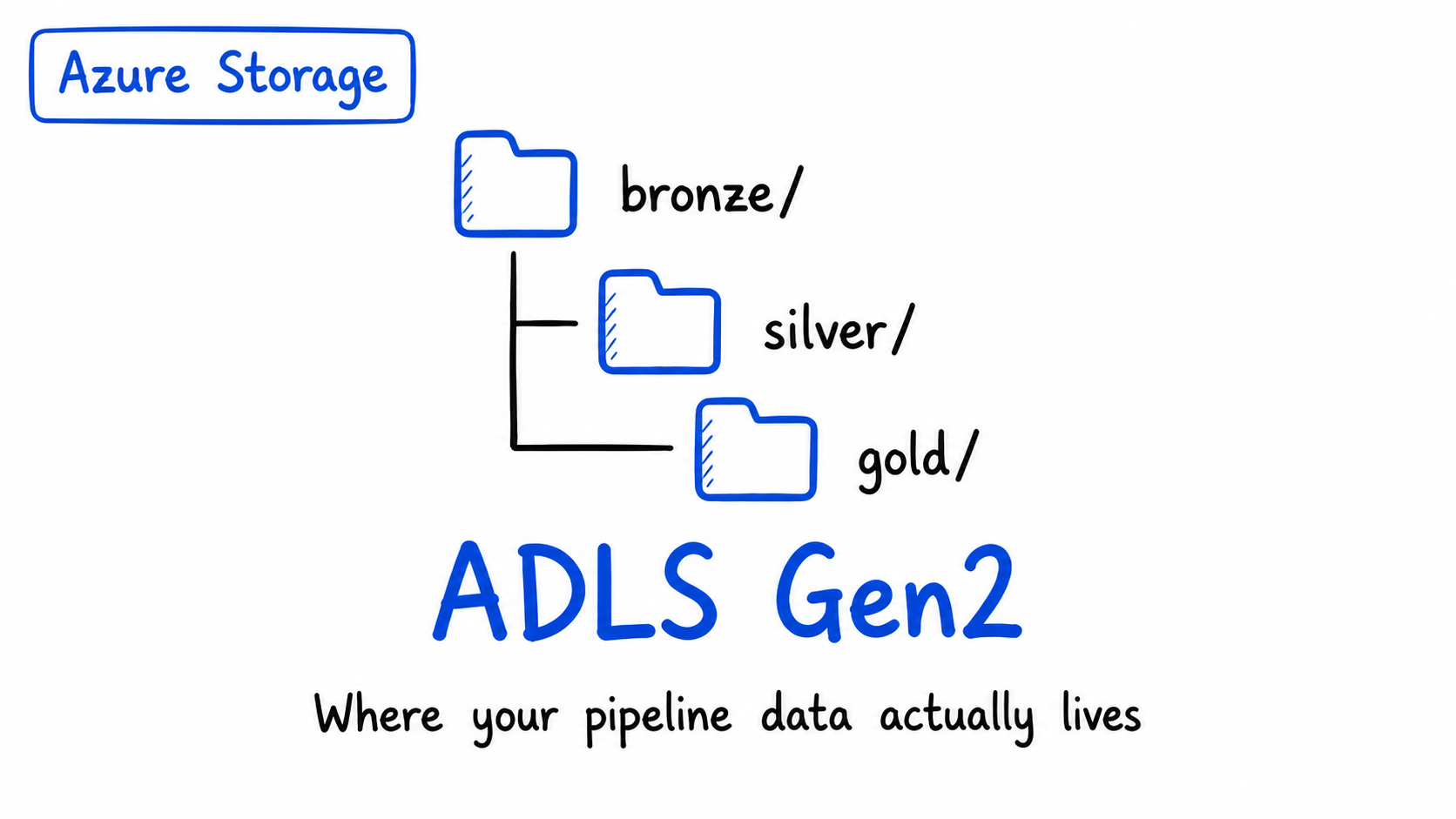
Azure Storage & ADLS Gen2: Where Does Your Data Actually Live?
Azure Storage and Azure Data Lake Storage Gen2 (ADLS Gen2) are two different storage solutions offered by Microsoft Azure. Azure Storage is a general-purpose storage service that provides various types of storage, including blobs, files, queues, and tables. ADLS Gen2, on the other hand, is a specialized storage solution designed for big data analytics workloads, offering features like hierarchical namespace and optimized performance for analytics.
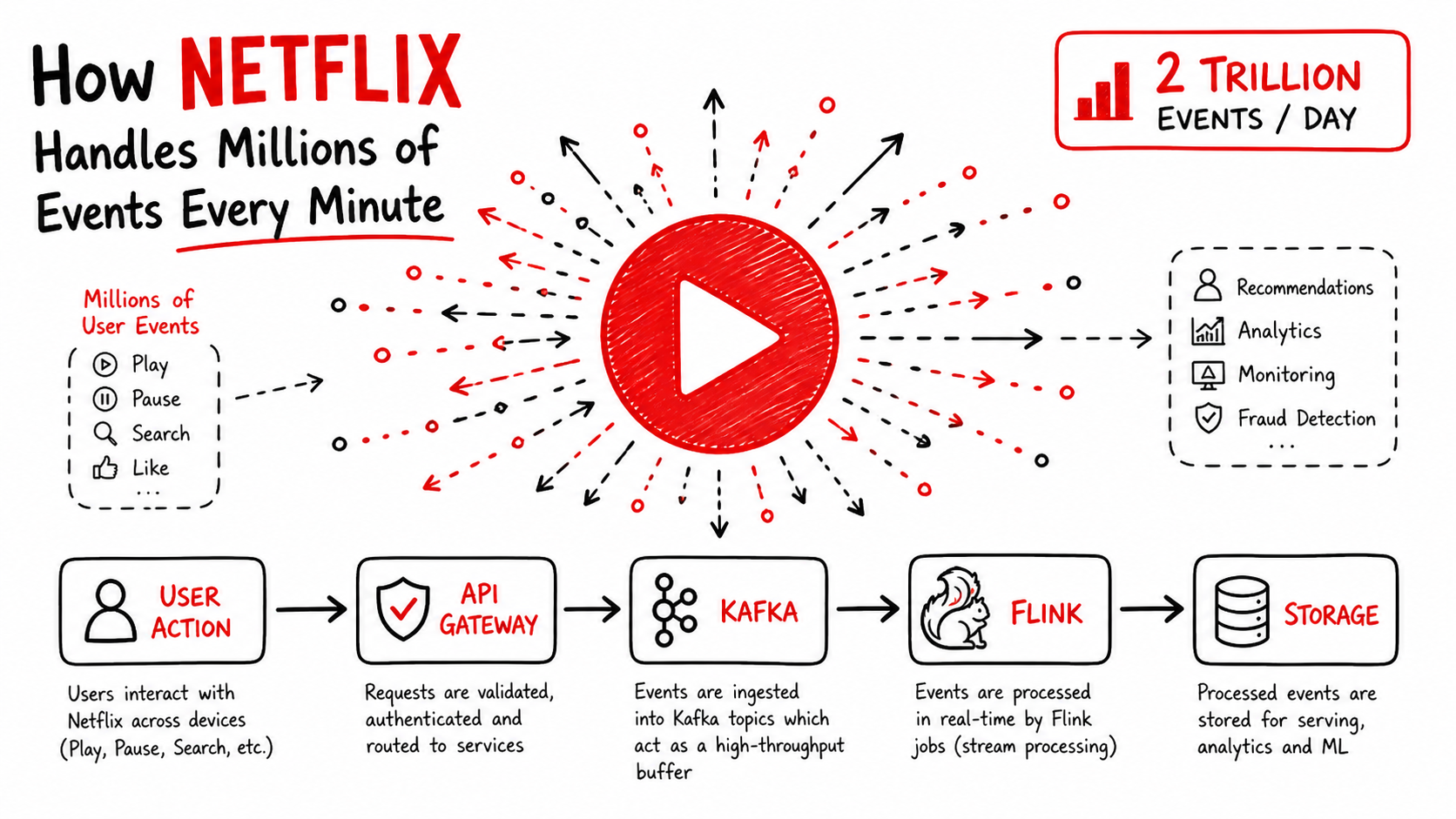
How Netflix Handles 2 Trillion Events Every Day
Netflix processes an enormous amount of data every day, handling over 2 trillion events. This article explores how they manage this massive scale and the technologies they use to ensure smooth operations.
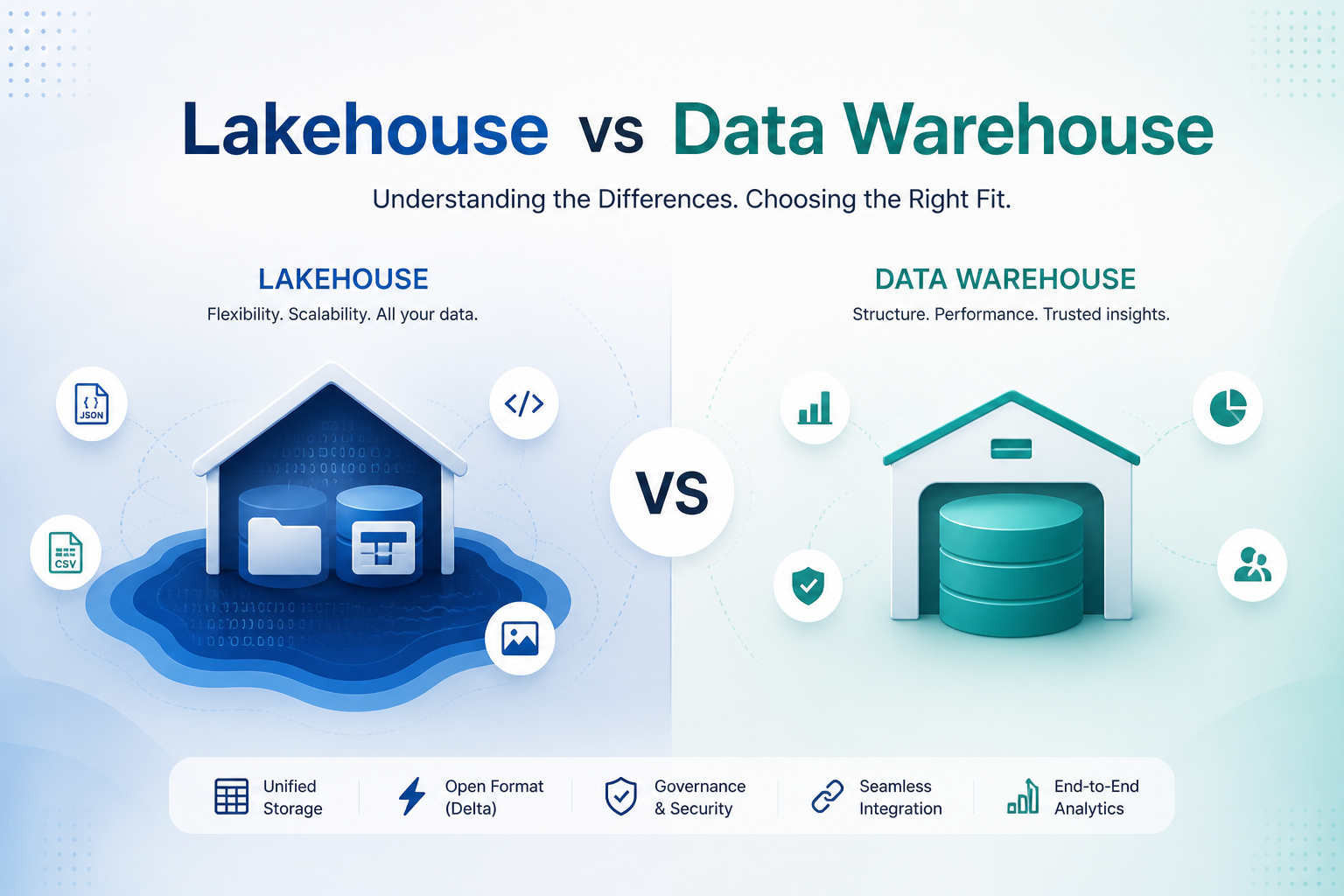
Lakehouse vs Data Warehouse: A Comprehensive Comparison
Lakehouse and Data Warehouse are two different data storage architectures. A Data Warehouse is a centralized repository for structured data, optimized for reporting and analysis. A Lakehouse combines the best of both worlds, allowing for the storage of both structured and unstructured data, providing flexibility and scalability.
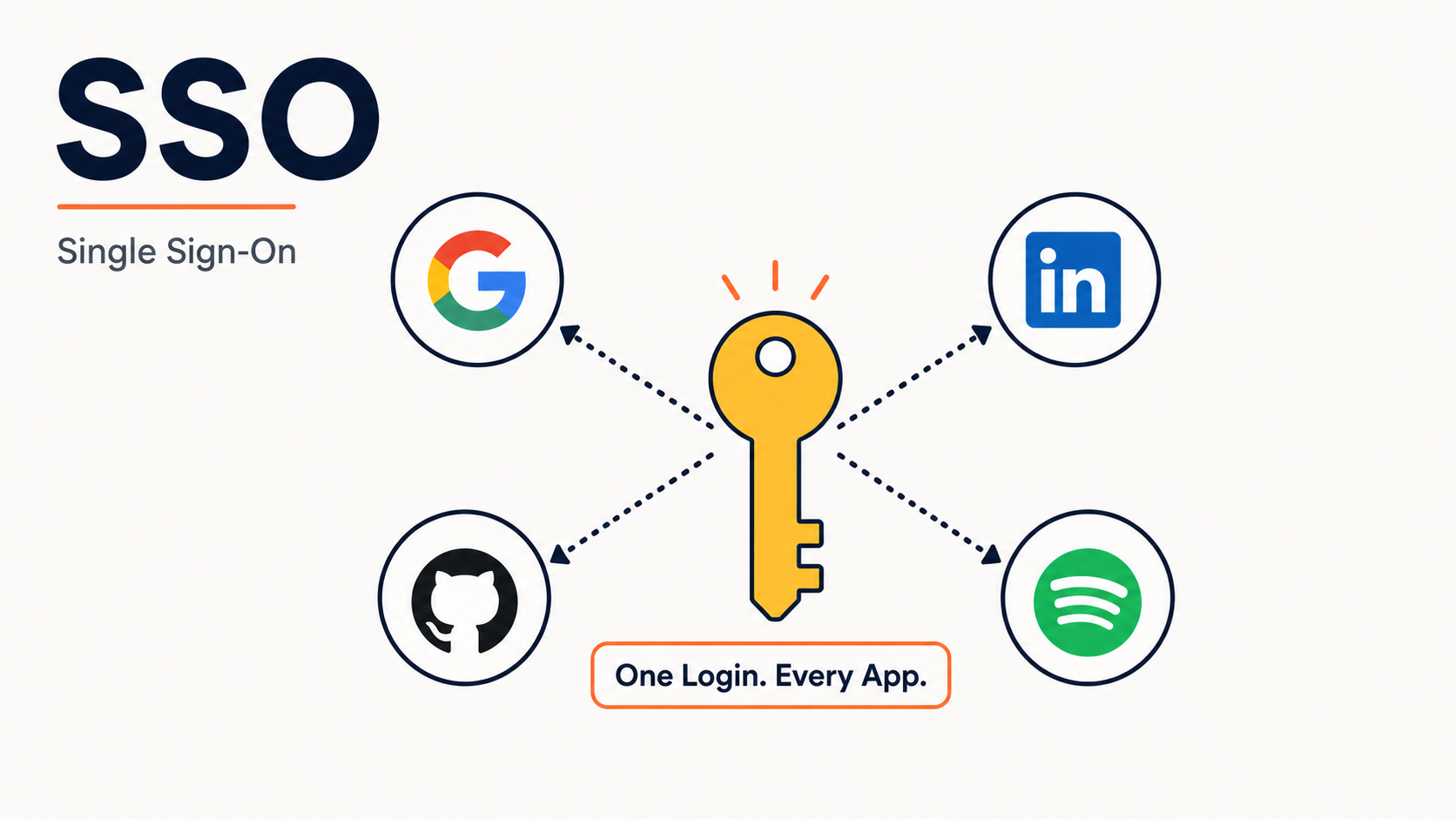
How SSO Actually Works
SSO lets you log into dozens of apps with a single set of credentials. But how does it actually work under the hood? A beginner-friendly walkthrough of the full flow — from clicking 'Sign in with Google' to getting access — step by step.

Microsoft Fabric: One Platform, One Lake, Every Data Workload
Microsoft Fabric is a unified analytics platform that integrates various data services and tools to provide a seamless experience for data professionals, enabling them to manage and analyze data across the entire data lifecycle.
How I Cleared the Azure Data Engineer Associate Certification
The Microsoft Certified: Azure Data Engineer Associate certification validates your skills in designing and implementing data solutions on the Azure platform.
Delta Lake: An Introduction to Trustworthy Data Storage
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads.
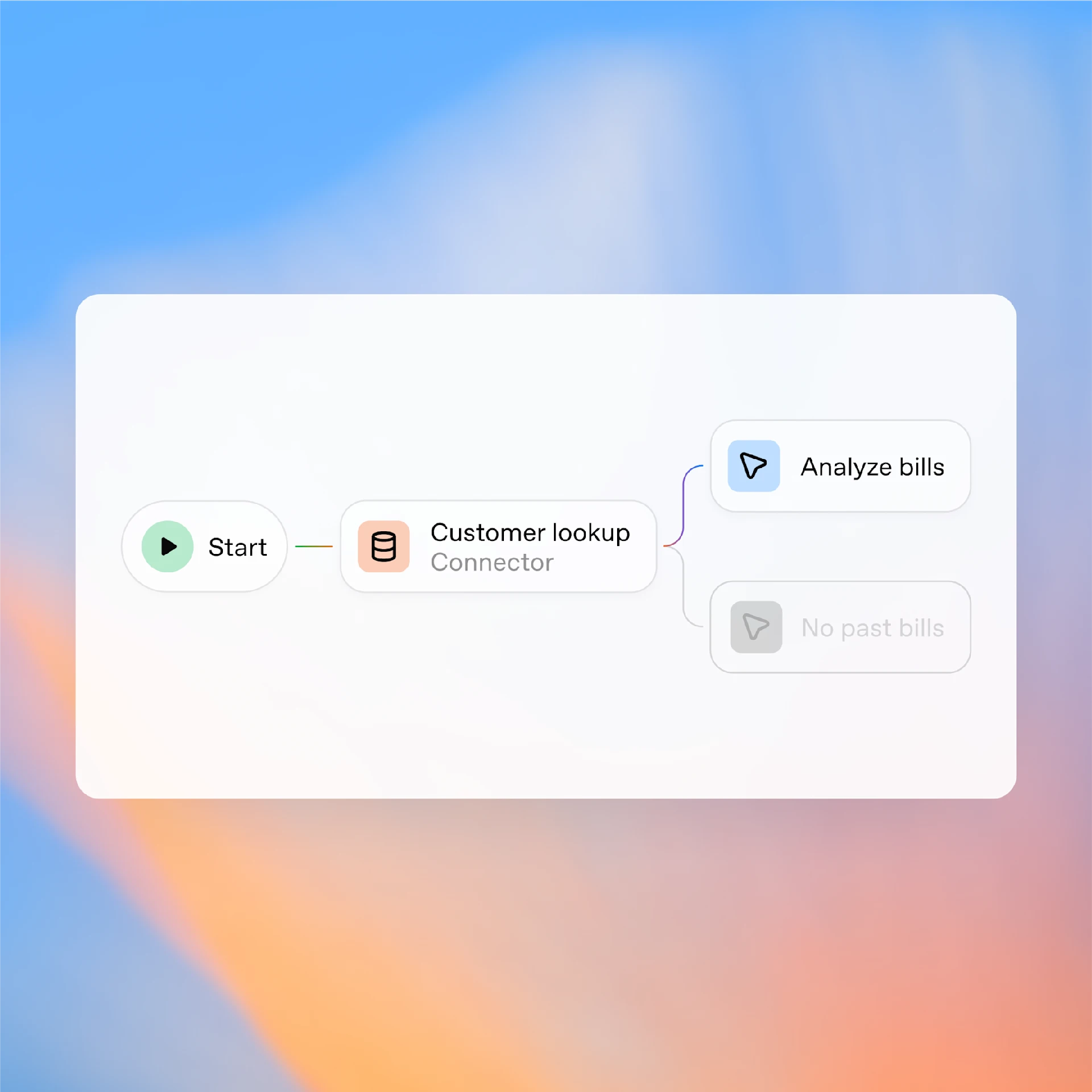
OpenAI AgentKit: Building AI Agents Without the Complexity
OpenAI AgentKit is a framework that simplifies the process of building AI agents, allowing developers to create intelligent applications without getting bogged down in the underlying complexities.
N8N: The Future of Workflow Automation
N8N is an open-source workflow automation tool that enables users to connect various apps and services to automate tasks without extensive coding knowledge.

Apache Spark Architecture Explained
Apache Spark is a fast, open-source big data framework that leverages in-memory computing for high performance. Its architecture powers scalable distributed processing across clusters, making it essential for analytics and machine learning.
What is GitHub Copilot
The GitHub Copilot Coding Agent is an asynchronous software engineering agent that assists developers by suggesting code snippets

Land a Job in UI/UX Design
Are you passionate about design and dreaming of a career in it? Or maybe you are already in the design space and looking to pivot into UI/UX?
Showing 1 - 12 of 21 posts